Экспорт всех совпадений регулярных выражений в Textpad или Notepad++ в виде списка
В Textpad или Notepad++ есть ли возможность экспортировать все совпадения для поиска по регулярному выражению в виде одного списка?
В большом текстовом файле я ищу теги (слова, заключенные в% %), используя регулярное выражение %\< and \>%и хочу, чтобы все совпадения были в одном списке, чтобы я мог удалить дубликаты с помощью Excel и получить список уникальных тегов.
5 ответов
Вы можете достичь этого, используя функции Backreferences и Find and Mark в Notepad++.
Найти совпадения с помощью регулярных выражений (скажем,
%(.*?)%) и заменить его на\n%\1%\nпосле этого у нас будет целевое слово в отдельных строках (т.е. ни в одной строке не будет более одного совпавшего слова)Используйте функцию Поиск -> Найти -> Отметить, чтобы пометить каждую строку регулярным выражением
%(.*?)%и не забудьте пометить "Линия закладок", прежде чем отмечать текст- Выберите Поиск -> Закладка -> Удалить неотмеченные строки
- Сохраните оставшийся текст. Это обязательный список.
Является ли это в Notepad++ обязательным требованием? Вы на Windows или в какой-то форме Unix? Если вы работаете в Windows, вы можете сделать это (частично) из командной строки:
findstr / r "% [az].*[az] %% [az]%" ваш_файл > новый_файл
findstr смутно вдохновлен grep, так что этот новый_файл будет содержать все строки, соответствующие вашим критериям поиска; затем вы можете использовать Notepad++ для удаления нежелательного текста (слева от первого% и справа от второго).
И, конечно же, если вы работаете в Unix, вы можете выполнить аналогичную задачу с sed,
Существует плагин Notepad++, который может копировать совпадающее выражение регулярного выражения в новый файл на новой вкладке. REGEXEXTRACT
Поскольку я не нашел никакого плагина для Notepad++, который мог бы извлечь какой-либо текст из текущего документа или всех файлов из местоположения с некоторыми дополнительными настройками (например, преобразование регистра), я решил попробовать сделать это сам. (...) Интерфейс плагина довольно прост (...). (...) В полях "Найти", "Заменить" и "Маска" используется синтаксис регулярного выражения C++11. Извлечение из файлов работает сейчас только для тех, кто в UTF8.
Редактировать диалог ввода с учетом вопроса
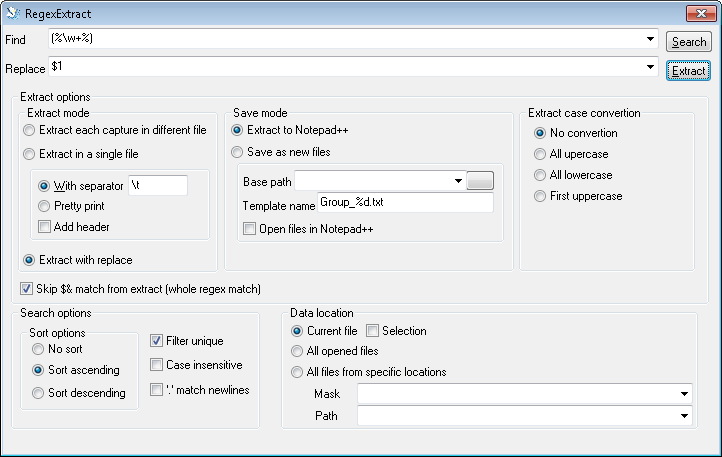
На картинке вы можете увидеть, как заполнить диалог. Я предполагаю, что слово не содержит пробелов и т. Д., Только символы, совпадающие с \ w. В частности:
- Используйте пару скобок, чтобы позволить выбрать слово, без символов percetange.
- Выберите опцию Извлечь с заменой, чтобы выбрать первое совпадение. В противном случае вы получите столбчатый вывод всех $1, $2 и т. Д.
- Установите флажок Пропустить $& ..., чтобы пропустить полные совпадения.
- Установите флажок Фильтр, чтобы сообщить о каждом совпадении только один раз.
- Нажмите " Извлечь", чтобы выбрать результат. (Поиск только находит совпадения, но не сообщает).
В TextPad вы бы подняли Find как обычно, затем используйте Mark All кнопка.
Оттуда используйте Copy Bookmarked Lines функция. (Меню "Правка"> "Копировать другие"> "Линии с закладками".)
Если кого-то интересует онлайн-решение (поскольку плагин notepad++ не работает на 64-битной версии), вы можете попробовать Molbiotools , он может полностью извлечь ваше регулярное выражение без дополнительных строк или с ними.