Как сравнить двоичные файлы в Linux?
Мне нужно сравнить два двоичных файла и получить вывод в виде:
за каждый другой байт. Так что если file1.bin является
00 90 00 11
в двоичном виде и file2.bin является
00 91 00 10
Я хочу получить что-то вроде
00000001 90 91
00000003 11 10
Есть ли способ сделать это в Linux? Я знаю о cmp -l но он использует десятичную систему для смещений и восьмеричную для байтов, которых я хотел бы избежать.
18 ответов
Это напечатает смещение и байты в шестнадцатеричном виде:
cmp -l file1.bin file2.bin | gawk '{printf "%08X %02X %02X\n", $1, strtonum(0$2), strtonum(0$3)}'
Или сделать $1-1 чтобы первое напечатанное смещение начиналось с 0.
cmp -l file1.bin file2.bin | gawk '{printf "%08X %02X %02X\n", $1-1, strtonum(0$2), strtonum(0$3)}'
К несчастью, strtonum() специфично для GAWK, поэтому для других версий awk - например, mawk - вам нужно будет использовать функцию преобразования восьмеричного числа в десятичное. Например,
cmp -l file1.bin file2.bin | mawk 'function oct2dec(oct, dec) {for (i = 1; i <= length(oct); i++) {dec *= 8; dec += substr(oct, i, 1)}; return dec} {printf "%08X %02X %02X\n", $1, oct2dec($2), oct2dec($3)}'
Вычеркнуто для удобства чтения:
cmp -l file1.bin file2.bin |
mawk 'function oct2dec(oct, dec) {
for (i = 1; i <= length(oct); i++) {
dec *= 8;
dec += substr(oct, i, 1)
};
return dec
}
{
printf "%08X %02X %02X\n", $1, oct2dec($2), oct2dec($3)
}'
Как сказал Кряк:
% xxd b1 > b1.hex
% xxd b2 > b2.hex
А потом
% diff b1.hex b2.hex
или же
% vimdiff b1.hex b2.hex
diff + xxd
Пытаться diff в следующей комбинации замещения процесса zsh/bash и colordiff в CLI:
diff -y <(xxd foo1.bin) <(xxd foo2.bin) | colordiff
Куда:
-yпоказывает различия между собой (необязательно)xxdинструмент CLI для создания вывода hexdump двоичного файла- добавлять
-W200вdiffдля более широкого вывода (по 200 символов в строке)
colordiff + xxd
Если вы colordiff, это может раскрасить diff вывод, например:
colordiff -y <(xxd foo1.bin) <(xxd foo2.bin)
В противном случае установите через: sudo apt-get install colordiff ,
Пример вывода:

vimdiff + xxd
Вы также можете использовать vimdiff например,
vimdiff <(xxd foo1.bin) <(xxd foo2.bin)
подсказки:
- если файлы слишком большие, добавьте ограничение (например,
-l1000) для каждогоxxd
Метод, который работает для добавления / удаления байтов
diff <(od -An -tx1 -w1 -v file1) \
<(od -An -tx1 -w1 -v file2)
Создайте тестовый пример с единственным удалением байта 64:
for i in `seq 128`; do printf "%02x" "$i"; done | xxd -r -p > file1
for i in `seq 128`; do if [ "$i" -ne 64 ]; then printf "%02x" $i; fi; done | xxd -r -p > file2
Выход:
64d63
< 40
Если вы также хотите увидеть ASCII-версию персонажа:
bdiff() (
f() (
od -An -tx1c -w1 -v "$1" | paste -d '' - -
)
diff <(f "$1") <(f "$2")
)
bdiff file1 file2
Выход:
64d63
< 40 @
Проверено на Ubuntu 16.04.
я предпочитаю od над xxd так как:
- это POSIX,
xxdнет (поставляется с Vim) - имеет
-Anудалить адресную колонку безawk,
Объяснение команды:
-Anудаляет адресную колонку Это важно, иначе все строки будут отличаться после добавления / удаления байта.-w1помещает один байт в строку, чтобы diff мог его использовать. Крайне важно иметь один байт на строку, иначе каждая строка после удаления окажется не в фазе и будет отличаться. К сожалению, это не POSIX, но присутствует в GNU.-tx1это представление, которое вы хотите, замените любое возможное значение, пока вы сохраняете 1 байт на строку.-vпредотвращает повторение звездочки*которые могут мешать разницеpaste -d '' - -соединяет каждые две строки. Нам это нужно, потому что гекс и ASCII идут в отдельные соседние строки. Взято из: https://stackoverflow.com/questions/8987257/concatenating-every-other-line-with-the-next- мы используем круглые скобки
()определитьbdiffвместо{}ограничить сферу внутренней функцииfсм. также: https://stackoverflow.com/questions/8426077/how-to-define-a-function-inside-another-function-in-bash
Смотрите также:
Короткий ответ
vimdiff <(xxd -c1 -p first.bin) <(xxd -c1 -p second.bin)
При использовании hexdumps и text diff для сравнения двоичных файлов, особенно xxdдобавление и удаление байтов становятся изменениями в адресации, что может затруднить просмотр. Этот метод говорит xxd не выводить адреса и выводить только один байт на строку, что, в свою очередь, показывает, какие именно байты были изменены, добавлены или удалены. Вы можете найти адреса позже, ища интересные последовательности байтов в более "нормальном" hexdump (вывод xxd first.bin).
Я бы порекомендовал hexdump для выгрузки двоичных файлов в текстовый формат и kdiff3 для просмотра различий.
hexdump myfile1.bin > myfile1.hex
hexdump myfile2.bin > myfile2.hex
kdiff3 myfile1.hex myfile2.hex
Инструмент анализа прошивки binwalk также имеет это как особенность через его -W / --hexdump опция командной строки, которая предлагает опции, такие как показ только отличающихся байтов:
-W, --hexdump Perform a hexdump / diff of a file or files
-G, --green Only show lines containing bytes that are the same among all files
-i, --red Only show lines containing bytes that are different among all files
-U, --blue Only show lines containing bytes that are different among some files
-w, --terse Diff all files, but only display a hex dump of the first file
В примере ОП при выполнении binwalk -W file1.bin file2.bin:
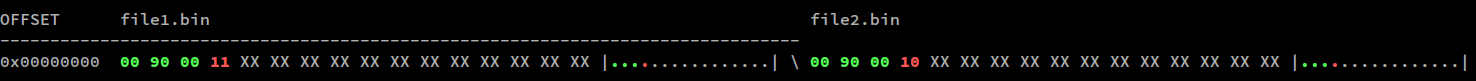
hexdiff это программа, предназначенная для того, чтобы делать именно то, что вы ищете.
Использование:
hexdiff file1 file2
Он отображает шестнадцатеричный (и 7-битный ASCII) двух файлов один над другим с выделением любых различий. смотреть на man hexdiff для команд, чтобы перемещаться в файле, и простой q выйдет
Возможно, он не совсем отвечает на вопрос, но я использую это для сравнения двоичных файлов:
gvim -d <(xxd -c 1 ~/file1.bin | awk '{print $2, $3}') <(xxd -c 1 ~/file2.bin | awk '{print $2, $3}')
Он распечатывает оба файла в виде шестнадцатеричных и ASCII- значений, по одному байту на строку, а затем использует средство сравнения Vim для визуальной визуализации.
Как сравнить двоичные файлы, шестнадцатеричные файлы и шестнадцатеричные файлы прошивки Intel с
Зеркало, зеркало на стене, какое решение самое удивительное из всех?
Вот этот: !-точно! Я проголосовал за это. Теперь позвольте мне показать вам, как это потрясающе выглядит и как легко его использовать:
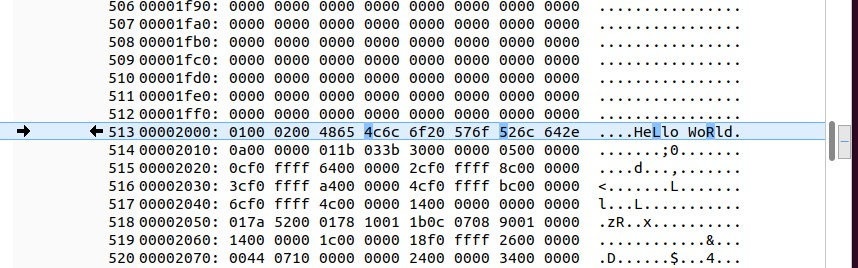
Краткое резюме
Загрузите последнюю версию моей функции в репозитории eRCaGuy_dotfiles здесь: .bash_useful_functions. Скопируйте и вставьте эту функцию в конец файла. Затем обновите свой~/.bashrcфайл с. ~/.bashrc. Наконец, используйте мою функцию следующим образом:
# pass multiple `.hex` files to convert to `.bin`, `.xxd.hex`, and
# `.xxd_short.hex` files
hex2xxdhex path/to/myfile1.hex path/to/myfile2.hex
# then compare the two output ".xxd.hex" or ".xxd_short.hex" files with `meld`
meld path/to/myfile1.xxd_short.hex path/to/myfile2.xxd_short.hex
meld path/to/myfile1.xxd.hex path/to/myfile2.xxd.hex
В приведенном выше сравнении двух*.xxd*.hexфайлов, вы увидите все шестнадцатеричные символы, за которыми следуют двоичные символы/символы ASCII в столбце справа, что позволяет вам легче определить различия в шестнадцатеричных файлах между двумя файлами.
Файлы такие же, как и файлы, за исключением того, что все строки, содержащие только нули, удалены. Таким образом, если ваш шестнадцатеричный файл помещает части вашей прошивки в совершенно разные адреса, все дополненные нули между двумя адресами будут удалены.
Если ваш первоначальный файл имеет размер 3,5 МБ, ваш файл может иметь размер 45 МБ..xxd.hexразмер файла может составлять 200 МБ, а ваш файл (со всеми строками из чистых нулей) — 5 МБ. может прекрасно сравнить два файла по 5 МБ, но с файлами по 200 МБ у него проблемы. Вот почему я генерирую.xxd_short.hexверсия тоже.
Другие варианты:
# Compare **two** binary files in meld
meld <(xxd file1.bin) <(xxd file2.bin)
# Compare **three** binary files in meld
meld <(xxd file1.bin) <(xxd file2.bin) <(xxd file3.bin)
# (note that for regular text files, just do this)
meld file1.txt file2.txt
# Compare ASCII hex files which were previously created with
# `xxd file1.bin file1.hex`
meld file1.hex file2.hex
# one-liner to compare Intel hex my_firmware1.hex and my_firmware2.hex
objcopy --input-target=ihex --output-target=binary my_firmware1.hex 1.bin \
&& objcopy --input-target=ihex --output-target=binary my_firmware2.hex 2.bin \
&& meld <(xxd 1.bin) <(xxd 2.bin)
# one-liner to compare Intel hex my_firmware1.hex and my_firmware2.hex
# **with the Microchip XC32 compiler toolchain!**
xc32-objcopy --input-target=ihex --output-target=binary my_firmware1.hex 1.bin \
&& xc32-objcopy --input-target=ihex --output-target=binary my_firmware2.hex 2.bin \
&& meld <(xxd 1.bin) <(xxd 2.bin)
# Compare two binary files using CLI tools only (no `meld` GUI) since you might
# be ssh'ed onto a remote machine
diff -u --color=always <(xxd file1.bin) <(xxd file2.bin) | less -RFX
# Another nice tool to use, which is CLI-based, but GUI-like (probably via the
# `ncurses` library, I'm guessing)
vbindiff file1.bin file2.bin
Подробности:
Сравнить двоичные файлы с
Сначала установите его в Linux Ubuntu с помощьюsudo apt install meld. Затем используйте его для сравнения двоичных файлов следующим образом:
# Compare binary files in meld
meld <(xxd file1.bin) <(xxd file2.bin)
# (note that for regular text files, just do this)
meld file1.txt file2.txt
Первая команда выше дает вам такое представление, выделяя точные различия на построчном и посимвольном уровне между левым и правым файлами. Обратите также внимание на выделенные полосы на правой полосе прокрутки, которые указывают, где строки во всем файле различаются:
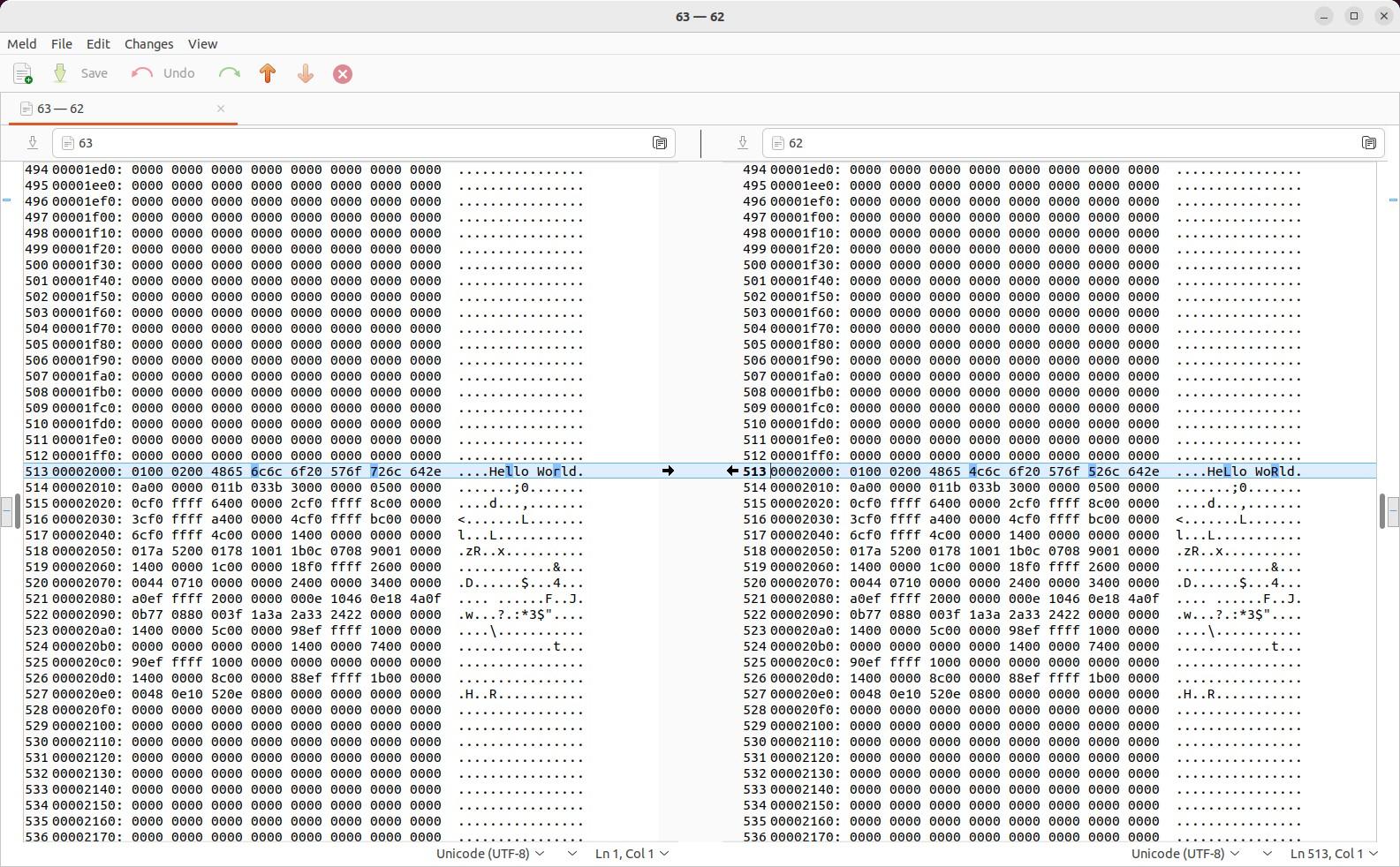
Навигация в Meld:
- Вы можете найти следующее изменение с помощью Alt+ Downи предыдущее изменение с помощью Alt+ Up.
- Или вы можете навести курсор на центральное пространство точно между левой и правой сторонами и прокручивать колесо мыши вверх и вниз, чтобы переходить между изменениями.
- Вы можете ввести и отредактировать левую или правую часть, а затем сохранить.
- Вы можете использовать Ctrl+ Fслева или справа для поиска.
- Ограничение: он не будет искать переносы строк. Для этого попробуйте вместо этого.
Отличный инструмент! Я собираюсь широко использовать это сейчас, когда сравниваю файлы прошивки микроконтроллера, чтобы выявить незначительные различия между некоторыми сборками, такие как измененные IP-адреса, встроенные имена файлов или временные метки.
Гениальность приведенной выше команды заключается в том, как она сначала преобразует двоичный файл в шестнадцатеричное + двоичное представление ASCII-текстовой боковой панели, чтобы вы могли видеть удобочитаемый текст, а также шестнадцатеричный код.
Сравните стандартные файлы с
Возможно, вы ранее конвертировали двоичные файлы в файлы, например:
# convert binary files to ASCII hex files with a human-readable binary
# ASCII-text-side-bar on the right
xxd file1.bin file1.hex
xxd file2.bin file2.hex
В этом случае просто используйте напрямую:
meld file1.hex file2.hex
Сравните файлы прошивки микроконтроллера Intel с
Интекс.hexфайлы не имеют красивой, удобочитаемой двоичной текстовой ASCII-панели справа. Итак, сначала мы должны преобразовать их в двоичный формат..binфайлы, используя, как показано в этом ответе , вот так:
# Convert an Intel hex firmware file to binary
objcopy --input-target=ihex --output-target=binary my_firmware1.hex my_firmware1.bin
objcopy --input-target=ihex --output-target=binary my_firmware2.hex my_firmware2.bin
Не забывайте _my_firmware1.binчасть в конце, иначе вы получите неожиданное поведение:my_firmware1.hexбудет преобразован в двоичный формат на месте! О, нет! Вот и ваш шестнадцатеричный файл!
Теперь сравните двоичные файлы в , используяxxdчтобы преобразовать их обратно в шестнадцатеричный формат ASCII с помощью удобной для чтения боковой панели:
meld <(xxd my_firmware1.bin) <(xxd my_firmware2.bin)
Еще лучше, выполните оба вышеуказанных шага за один, как в этом «однострочнике»:
# one-liner to compare my_firmware1.hex and my_firmware2.hex
objcopy --input-target=ihex --output-target=binary my_firmware1.hex 1.bin \
&& objcopy --input-target=ihex --output-target=binary my_firmware2.hex 2.bin \
&& meld <(xxd 1.bin) <(xxd 2.bin)
Имейте в виду, что для выполнения вышеуказанных операций вам необходимо использовать версию исполняемого файла вашего компилятора . Так, например, для набора инструментов компилятора Microchip MPLAB X XC32 используйтеxc32-objcopyвместоobjcopy:
# one-liner to compare my_firmware1.hex and my_firmware2.hex
# **with the Microchip XC32 compiler toolchain!**
xc32-objcopy --input-target=ihex --output-target=binary my_firmware1.hex 1.bin \
&& xc32-objcopy --input-target=ihex --output-target=binary my_firmware2.hex 2.bin \
&& meld <(xxd 1.bin) <(xxd 2.bin)
Использование только инструментов CLI без графического интерфейса (это графический интерфейс)...
Если вам действительно нужно использовать инструменты без графического интерфейса, например, через сеанс ssh, вот еще несколько вариантов. В качестве альтернативы вы можете простоscpфайл обратно на ваш локальный компьютер через ssh, а затем используйте, как описано выше.
Инструменты чистого CLI для двоичного сравнения:
Использовать
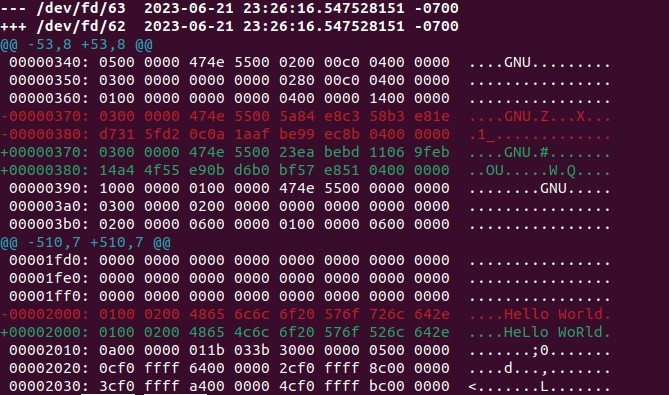
diff: вернитесь к от @kenorbответу @kenorb выше ]. Вот некоторые из моих собственных рассуждений об этих командах, которые я считаю более полезными:# For short output diff -u --color=always <(xxd file1.bin) <(xxd file2.bin) # If your output is really long, pipe to `less -RFX`, like `git` does diff -u --color=always <(xxd file1.bin) <(xxd file2.bin) | less -RFXПример запуска и вывода:
eRCaGuy_hello_world/c$ diff -u --color=always <(xxd file1.bin) <(xxd file2.bin) --- /dev/fd/63 2023-06-21 23:16:51.649582608 -0700 +++ /dev/fd/62 2023-06-21 23:16:51.649582608 -0700 @@ -53,8 +53,8 @@ 00000340: 0500 0000 474e 5500 0200 00c0 0400 0000 ....GNU......... 00000350: 0300 0000 0000 0000 0280 00c0 0400 0000 ................ 00000360: 0100 0000 0000 0000 0400 0000 1400 0000 ................ -00000370: 0300 0000 474e 5500 5a84 e8c3 58b3 e81e ....GNU.Z...X... -00000380: d731 5fd2 0c0a 1aaf be99 ec8b 0400 0000 .1_............. +00000370: 0300 0000 474e 5500 23ea bebd 1106 9feb ....GNU.#....... +00000380: 14a4 4f55 e90b d6b0 bf57 e851 0400 0000 ..OU.....W.Q.... 00000390: 1000 0000 0100 0000 474e 5500 0000 0000 ........GNU..... 000003a0: 0300 0000 0200 0000 0000 0000 0000 0000 ................ 000003b0: 0200 0000 0600 0000 0100 0000 0600 0000 ................ @@ -510,7 +510,7 @@ 00001fd0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001fe0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001ff0: 0000 0000 0000 0000 0000 0000 0000 0000 ................ -00002000: 0100 0200 4865 6c6c 6f20 576f 726c 642e ....Hello World. +00002000: 0100 0200 4865 4c6c 6f20 576f 526c 642e ....HeLlo WoRld. 00002010: 0a00 0000 011b 033b 3000 0000 0500 0000 .......;0....... 00002020: 0cf0 ffff 6400 0000 2cf0 ffff 8c00 0000 ....d...,....... 00002030: 3cf0 ffff a400 0000 4cf0 ffff bc00 0000 <.......L.......Вот скриншот, чтобы вам было легче увидеть изменения цвета:
Использовать
vbindiff: Впервые я узнал об этом инструменте здесь: How-To Geek: Как сравнить двоичные файлы в Linux.Вот как его установить и использовать:
# 1. Install it sudo apt update sudo apt install vbindiff # 2. use it; note that we do NOT need `xxd` here vbindiff file1.bin file2.bin # You should study the manual/help pages too. It is very useful: vbindiff -h man vbindiffВот как это выглядит на втором изменении, показанном выше. Как видите, точные различия символов выделены красным цветом. Это довольно хороший инструмент:

Навигация:
- Видеть
man vbindiffдля получения подробной информации. Это короткое и простое руководство. - Нажмите Spaceили Enterдля перехода к следующему различию. Я Spaceдважды нажал, чтобы перейти ко второй разнице на скриншоте выше.
- Нажмите Qили Escдля выхода.
- Пролистывать можно с помощью колеса прокрутки мыши, клавиш со стрелками, PageUp/Downклавиш и т. д.
- Нажмите T, чтобы включить прокрутку только верхнего окна.
- Нажмите B, чтобы включить прокрутку только нижнего окна.
- Нажмите F, чтобы найти.
Навигация действительно довольно ограничена. Я не вижу способа вернуться назад и найти предыдущее изменение. Просто выйти и начать заново.
- Видеть
Как я создал двоичные файлы, используемые в примерах выше?
Легкий:
file1.c из моего репозитория eRCaGuy_hello_world здесь: hello_world_extra_basic.c:
#include <stdbool.h> // For `true` (`1`) and `false` (`0`) macros in C
#include <stdint.h> // For `uint8_t`, `int8_t`, etc.
#include <stdio.h> // For `printf()`
// int main(int argc, char *argv[]) // alternative prototype
int main()
{
printf("Hello World.\n\n");
return 0;
}
файл2.с:
#include <stdbool.h> // For `true` (`1`) and `false` (`0`) macros in C
#include <stdint.h> // For `uint8_t`, `int8_t`, etc.
#include <stdio.h> // For `printf()`
// int main(int argc, char *argv[]) // alternative prototype
int main()
{
printf("HeLlo WoRld.\n\n");
return 0;
}
Теперь создайте исполняемые файлы,file1.binиfile2.bin, из файлов C выше:
gcc -Wall -Wextra -Werror -O3 -std=gnu17 file1.c -o file1.bin && ./file1.bin
gcc -Wall -Wextra -Werror -O3 -std=gnu17 file2.c -o file2.bin && ./file2.bin
Тогда, конечно, сравните их!:
meld <(xxd file1.bin) <(xxd file2.bin)
Смотрите также
- Мой очень-полезный
hex2binиhex2xxdhexФункции Bash, которые помогут вам в двоичных сравнениях выше, в моем ответе здесь: Переполнение стека: функция Bash для массового преобразования Intel*.hexфайлы прошивки в*.binфайлы прошивки и*.xxd.hexфайлы для сравнения в - Мой ответ как сделать
meldтвойgit difftoolв Windows, Mac и Linux
Ниже приведен сценарий Perl, colorbindiff, который выполняет двоичное сравнение, принимая во внимание изменения байтов, а также добавление / удаление байтов (многие из предлагаемых здесь решений обрабатывают только изменения байтов), как в текстовом diff. Он также доступен на GitHub.
Он отображает результаты рядом с цветами, что значительно облегчает анализ.
Чтобы использовать это:
perl colorbindiff.pl FILE1 FILE2
Сценарий:
#!/usr/bin/perl
#########################################################################
#
# VBINDIFF.PL : A side-by-side visual diff for binary files.
# Consult usage subroutine below for help.
#
# Copyright (C) 2020 Jerome Lelasseux jl@jjazzlab.com
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
#
#########################################################################
use warnings;
use strict;
use Term::ANSIColor qw(colorstrip colored);
use Getopt::Long qw(GetOptions);
use File::Temp qw(tempfile);
use constant BLANK => "..";
use constant BUFSIZE => 64 * 1024; # 64kB
sub usage
{
print "USAGE: $0 [OPTIONS] FILE1 FILE2\n";
print "Show a side-by-side binary comparison of FILE1 and FILE2. Show byte modifications but also additions and deletions, whatever the number of changed bytes. Rely on the 'diff' external command such as found on Linux or Cygwin. The algorithm is not suited for large and very different files.\n";
print "Author: Jerome Lelasseux \@2021\n";
print "OPTIONS: \n";
print " --cols=N : display N columns of bytes.diff Default is 16.\n";
print " --no-color : don't colorize output. Needed if you view the output in an editor.\n";
print " --no-marker : don't use the change markers (+ for addition, - for deletion, * for modified).\n";
print " --no-ascii : don't show the ascii columns.\n";
print " --only-changes : only display lines with changes.\n";
exit;
}
# Command line arguments
my $maxCols = 16;
my $noColor = 0;
my $noMarker = 0;
my $noAscii = 0;
my $noCommon = 0;
GetOptions(
'cols=i' => \$maxCols,
'no-ascii' => \$noAscii,
'no-color' => \$noColor,
'no-marker' => \$noMarker,
'only-changes' => \$noCommon
) or usage();
usage() unless ($#ARGV == 1);
my ($file1, $file2) = (@ARGV);
# Convert input files into hex lists
my $fileHex1 = createHexListFile($file1);
my $fileHex2 = createHexListFile($file2);
# Process diff -y output to get an easy-to-read side-by-side view
my $colIndex = 0;
my $oldPtr = 0;
my $newPtr = 0;
my $oldLineBuffer = sprintf("0x%04X ", 0);
my $newLineBuffer = sprintf("0x%04X ", 0);
my $oldCharBuffer;
my $newCharBuffer;
my $isDeleting = 0;
my $isAdding = 0;
my $isUnchangedLine = 1;
open(my $fh, '-|', qq(diff -y $fileHex1 $fileHex2)) or die $!;
while (<$fh>)
{
# Parse line by line the output of the 'diff -y' on the 2 hex list files.
# We expect:
# "xx | yy" for a modified byte
# " > yy" for an added byte
# "xx <" for a deleted byte
# "xx xx" for identicial bytes
my ($oldByte, $newByte);
my ($oldChar, $newChar);
if (/\|/)
{
# Changed
if ($isDeleting || $isAdding)
{
printLine($colIndex);
}
$isAdding = 0;
$isDeleting = 0;
$isUnchangedLine = 0;
/([a-fA-F0-9]+)([^a-fA-F0-9]+)([a-fA-F0-9]+)/;
$oldByte = formatByte($1, 3);
$oldChar = toPrintableChar($1, 3);
$newByte = formatByte($3, 3);
$newChar = toPrintableChar($3, 3);
$oldPtr++;
$newPtr++;
}
elsif (/</)
{
# Deleted in new
if ($isAdding)
{
printLine($colIndex);
}
$isAdding = 0;
$isDeleting = 1;
$isUnchangedLine = 0;
/([a-fA-F0-9]+)/;
$oldByte=formatByte($1, 2);
$oldChar=toPrintableChar($1, 2);
$newByte=formatByte(BLANK, 2);
$newChar=colorize(".", 2);
$oldPtr++;
}
elsif (/>/)
{
# Added in new
if ($isDeleting)
{
printLine($colIndex);
}
$isAdding = 1;
$isDeleting = 0;
$isUnchangedLine = 0;
/([a-fA-F0-9]+)/;
$oldByte=formatByte(BLANK, 1);
$oldChar=colorize(".", 1);
$newByte=formatByte($1, 1);
$newChar=toPrintableChar($1, 1);
$newPtr++;
}
else
{
# Unchanged
if ($isDeleting || $isAdding)
{
printLine($colIndex);
}
$isDeleting = 0;
$isAdding = 0;
/([a-fA-F0-9]+)([^a-fA-F0-9]+)([a-fA-F0-9]+)/;
$oldByte=formatByte($1, 0);
$oldChar=toPrintableChar($1, 0);
$newByte=formatByte($3, 0);
$newChar=toPrintableChar($3, 0);
$oldPtr++;
$newPtr++;
}
# Append the bytes to the old and new buffers
$oldLineBuffer .= $oldByte;
$oldCharBuffer .= $oldChar;
$newLineBuffer .= $newByte;
$newCharBuffer .= $newChar;
$colIndex++;
if ($colIndex == $maxCols)
{
printLine();
}
}
printLine($colIndex); # Possible remaining line
#================================================================
# subroutines
#================================================================
# $1 a string representing a data byte
# $2 0=unchanged, 1=added, 2=deleted, 3=changed
# return the formatted string (color/maker)
sub formatByte
{
my ($byte, $type) = @_;
my $res;
if (!$noMarker)
{
if ($type == 0 || $byte eq BLANK) { $res = " " . $byte; } # Unchanged or blank
elsif ($type == 1) { $res = " +" . $byte; } # Added
elsif ($type == 2) { $res = " -" . $byte; } # Deleted
elsif ($type == 3) { $res = " *" . $byte; } # Changed
else { die "Error"; }
} else
{
$res = " " . $byte;
}
$res = colorize($res, $type);
return $res;
}
# $1 a string
# $2 0=unchanged, 1=added, 2=deleted, 3=changed
# return the colorized string according to $2
sub colorize
{
my ($res, $type) = @_;
if (!$noColor)
{
if ($type == 0) { } # Unchanged
elsif ($type == 1) { $res = colored($res, 'bright_green'); } # Added
elsif ($type == 2) { $res = colored($res, 'bright_red'); } # Deleted
elsif ($type == 3) { $res = colored($res, 'bright_cyan'); } # Changed
else { die "Error"; }
}
return $res;
}
# Print the buffered line
sub printLine
{
if (length($oldLineBuffer) <=10)
{
return; # No data to display
}
if (!$isUnchangedLine)
{
# Colorize and add a marker to the address of each line if some bytes are changed/added/deleted
my $prefix = substr($oldLineBuffer, 0, 6) . ($noMarker ? " " : "*");
$prefix = colored($prefix, 'magenta') unless $noColor;
$oldLineBuffer =~ s/^......./$prefix/;
$prefix = substr($newLineBuffer, 0, 6) . ($noMarker ? " " : "*");
$prefix = colored($prefix, 'magenta') unless $noColor;
$newLineBuffer =~ s/^......./$prefix/;
}
my $oldCBuf = $noAscii ? "" : $oldCharBuffer;
my $newCBuf = $noAscii ? "" : $newCharBuffer;
my $spacerChars = $noAscii ? "" : (" " x ($maxCols - $colIndex));
my $spacerData = ($noMarker ? " " : " ") x ($maxCols - $colIndex);
if (!($noCommon && $isUnchangedLine))
{
print "${oldLineBuffer}${spacerData} ${oldCBuf}${spacerChars} ${newLineBuffer}${spacerData} ${newCBuf}\n";
}
# Reset buffers and counters
$oldLineBuffer = sprintf("0x%04X ", $oldPtr);
$newLineBuffer = sprintf("0x%04X ", $newPtr);
$oldCharBuffer = "";
$newCharBuffer = "";
$colIndex = 0;
$isUnchangedLine = 1;
}
# Convert a hex byte string into a printable char, or '.'.
# $1 = hex str such as A0
# $2 0=unchanged, 1=added, 2=deleted, 3=changed
# Return the corresponding char, possibly colorized
sub toPrintableChar
{
my ($hexByte, $type) = @_;
my $char = chr(hex($hexByte));
$char = ($char =~ /[[:print:]]/) ? $char : ".";
return colorize($char, $type);
}
# Convert file $1 into a text file with 1 hex byte per line.
# $1=input file name
# Return the output file name
sub createHexListFile
{
my ($inFileName) = @_;
my $buffer;
my $in_fh;
open($in_fh, "<:raw", $inFileName) || die "$0: cannot open $inFileName for reading: $!";
my ($out_fh, $filename) = tempfile();
while (my $nbReadBytes = read($in_fh, $buffer, BUFSIZE))
{
my @hexBytes = unpack("H2" x $nbReadBytes, $buffer);
foreach my $hexByte (@hexBytes)
{
print $out_fh "$hexByte\n" || die "couldn't write to $out_fh: $!";
}
}
close($in_fh);
return $filename;
}
Вы можете использовать инструмент gvimdiff , который входит в пакет vim-gui-common
sudo apt-get update
sudo apt-get установить vim-gui-common
Затем вы можете сравнить 2 шестнадцатеричных файла, используя следующие команды:
ubuntu> gvimdiff <hex-file1> <hex-file2>
Это все. Надеюсь, что помощь!
Dhex http://www.dettus.net/dhex/
DHEX - это не просто еще один шестнадцатеричный редактор: он включает режим diff, который можно использовать для простого и удобного сравнения двух двоичных файлов. Поскольку он основан на ncurses и является темным, он может работать в любом количестве систем и сценариев. Благодаря использованию журналов поиска можно легко отслеживать изменения в разных итерациях файлов.
Я написал простой скрипт для сравнения двоичного файла. Он напечатает первый другой фрагмент (40 байт) и смещение:
https://gist.github.com/guyskk/98621a9785bd88cf2b4e804978950122
$ bindiff file1 file2
8880> 442408E868330300488D05825337004889042448C744240802000000E84F330300E88A2A0300488B
^^^^^^^^^ ^^
442408E868330300E59388E59388004889042448C744240802000000E84F330300E88A2A0300488B
Вот скрипт для использования kdiff3 для шестнадцатеричного вывода:
#!/bin/bash
mkdir -p ~/tmp/kdiff3/a
mkdir -p ~/tmp/kdiff3/b
a="$HOME/tmp/kdiff3/a/`basename $1`.hex"
b="$HOME/tmp/kdiff3/b/`basename $2`.hex"
xxd "$1" > "$a"
xxd "$2" > "$b"
kdiff3 "$a" "$b"
Который вы могли бы сохранить, например,kdiff3binи используйте как:
kdiff3bin file1.bin file2.bin
https://security.googleblog.com/2016/03/bindiff-now-available-for-free.html
BinDiff - это отличный инструмент для сравнения бинарных файлов, который был недавно открыт.
Продукт с открытым исходным кодом для Linux (и всего остального) - это Radare, который обеспечивает radiff2 явно для этого. Я проголосовал за это, потому что у меня и у других один и тот же вопрос в вопросе, который вы задаете
за каждый другой байт
Это безумие, хотя. Потому что, как и просили, если вы вставите один байт в первый байт в файле, вы обнаружите, что каждый последующий байт отличается, и поэтому diff будет повторять весь файл для фактической разницы в один байт.
Чуть более практичным является radiff -O, -O предназначен для "" Выполнение сравнения кода со всеми байтами, а не только с фиксированными байтами кода операции ""
0x000000a4 0c01 => 3802 0x000000a4
0x000000a8 1401 => 3802 0x000000a8
0x000000ac 06 => 05 0x000000ac
0x000000b4 02 => 01 0x000000b4
0x000000b8 4c05 => 0020 0x000000b8
0x000000bc 4c95 => 00a0 0x000000bc
0x000000c0 4c95 => 00a0 0x000000c0
Как и IDA Pro, Radare является основным инструментом для бинарного анализа, вы также можете показать дельта-диффузию с помощью -d или отобразить разобранные байты вместо шестнадцатеричного с помощью -D,
Если вы задаете такие вопросы, проверьте
- Переполнение стека для вопросов программного обеспечения,
- Обратный обмен стека
- Radare - х
radiff2для бинарного сравнения