Просмотр кодовых точек Unicode для всех букв в файле на Bash
Мне приходится иметь дело с файлом, который имеет много невидимых управляющих символов, таких как "справа налево" или "не присоединяемый с нулевой шириной", пробелами, отличными от нормального пробела и т. Д., И у меня возникают проблемы с этим.
Теперь я хотел бы как-то просмотреть все буквы в данном файле, буква за буквой (я хотел бы сказать "слева направо", но я, к сожалению, имею дело с языком справа налево), как кодовые точки Юникода, используя только основные инструменты Bash (как vi, less, cat...). Возможно ли это как-то?
Я знаю, что могу отобразить файл в шестнадцатеричном hexdump, но я должен был бы пересчитать кодовые точки. Я действительно хочу увидеть фактические кодовые точки Unicode, чтобы я мог найти их в Google и выяснить, что происходит.
редактировать: я добавлю, что я не хочу перекодировать его в другую кодировку (потому что это то, что я узнаю в Интернете). У меня есть файл в UTF8, и это нормально. Я просто хочу знать точные кодовые точки всех букв.
5 ответов
Я написал себе perl one-liner, который делает именно это, и он также печатает оригинальный символ. (Ожидается файл от STDIN)
perl -C7 -ne 'for(split(//)){print sprintf("U+%04X", ord)." ".$_."\n"}'
Однако должен быть лучший способ, чем этот.
Мне понадобился код для некоторых общих смайликов, и я придумал это:
echo -n "" | # -n ignore trailing newline \
iconv -f utf8 -t utf32be | # UTF-32 big-endian happens to be the code point \
xxd -p | # -p just give me the plain hex \
sed -r 's/^0+/0x/' | # remove leading 0's, replace with 0x \
xargs printf 'U+%04X\n' # pretty print the code point
какие отпечатки
U+1F60A
это кодовая точка для "УЛЫБАЮЩЕГО ЛИЦА С УЛЫБАЮЩИМИСЯ ГЛАЗАМИ".
Вдохновленный ответом Neftas, вот несколько более простое решение, которое работает со строками, а не с одним символом:
iconv -f utf8 -t utf32le | hexdump -v -e '8/4 "0x%04x " "\n"' | sed -re"s/0x / /g"
# ^
# The number `8` above determines the number of columns in the output. Modify as needed.
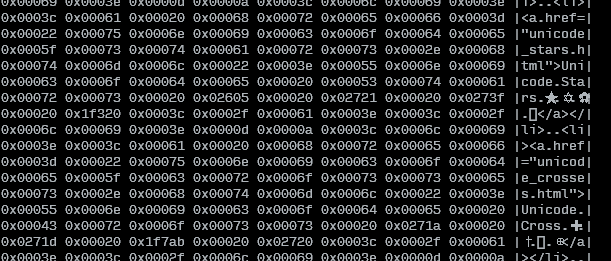
Я также создал скрипт Bash, который читает из стандартного ввода или из файла и отображает исходный текст вместе со значениями Unicode:
COLWIDTH=8
SHOWTEXT=true
tmpfile=$(mktemp)
cp "${1:-/dev/stdin}" "$tmpfile"
left=$(set -o pipefail; iconv -f utf8 -t utf32le "$tmpfile" | hexdump -v -e $COLWIDTH'/4 "0x%05x " "\n"' | sed -re"s/0x / /g")
if [ $? -gt 0 ]; then
echo "ERROR: Could not convert input" >&2
elif $SHOWTEXT; then
right=$(tr [:space:] . < "$tmpfile" | sed -re "s/.{$COLWIDTH}/|&|\n/g" | sed -re "s/^.{1,$((COLWIDTH+1))}\$/|&|/g")
pr -mts" " <(echo "$left") <(echo "$right")
else
echo "$left"
fi
rm "$tmpfile"
Это решение, требующееbashи используя только встроенные модули:
while IFS= read -d $'\000' -n 1 x; do printf '%X\n' "'$x"; done
Если вы хотите увидеть символы с их сопоставлениями, вы можете использовать это:
while IFS= read -d $'\000' -n 1 x; do printf '%2s -> %X\n' "$x" "'$x"; done
Например:
$ echo 'Hi! ' | while IFS= read -d $'\000' -n 1 x; do printf '%2s -> %X\n' "$x" "'$x"; done
H -> 48
i -> 69
! -> 21
-> 20
-> 1F60A
-> A
Примечание:
-
IFS=и-d $'\000'необходимы для отображения всех символов. Без них символы новой строки и разделители слов будут отображаться как нули, и это нормально, если вы этого предпочитаете.
$ echo 'Hi! ' | while read -n 1 x; do printf '%2s -> %X\n' "$x" "'$x"; done
H -> 48
i -> 69
! -> 21
-> 0
-> 1F60A
-> 0
Perl oneliner у меня не работал, и я не мог заставить методы hexdump отображать фактический символ, кроме кода, поэтому вот один python oneliner:
python -c 'import sys; print("\n".join(["\\u%04x -> %s" % (ord(c), c) for c in sys.stdin.read() if c.strip()]))'
Результат будет примерно таким:
$ cat test.txt
A á Ü Ñ 日本語 1 1 / _
$ python -c 'import sys; print("\n".join(["\\u%04x -> %s" % (ord(c), c) for c in sys.stdin.read() if c.strip()]))' < test.txt
\u0041 -> A
\u00e1 -> á
\u00dc -> Ü
\u00d1 -> Ñ
\u65e5 -> 日
\u672c -> 本
\u8a9e -> 語
\u0031 -> 1
\uff11 -> 1
\u002f -> /
\u005f -> _
Примечание: для python2 текст необходимо декодировать:
python2 -c 'import sys; print("\n".join(["\\u%04x -> %s" % (ord(c), c) for c in sys.stdin.read().decode("utf-8") if c.strip()]))'