Вывод команды не работает после изменения кодовой страницы
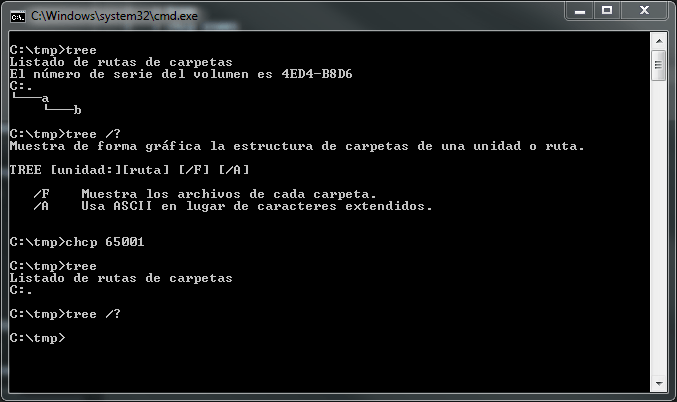
Я обнаружил довольно странную проблему при исследовании запутанного мира кодирования символов. В Windows, если я наберу "дерево", команда будет работать, как и ожидалось, но если я потом наберу "chcp 65001" (то есть UTF-8), а затем снова "дерево", то оно сломается.
т.е.
> tree
> chcp 65001
> tree
Это в Windows 7, vanilla cmd, испанский язык. Кроме того, при перенаправлении вывода в файл его содержимое остается одинаковым до и после chcp (полный "ÀÄÄÄa").
Некоторые исследования показали, что кодировка OEM-850.
Я знаю, что это выглядит лишним вопросом, но при компиляции программ (в основном с gcc) у меня та же проблема.
Переключатели /A и /U для cmd тоже не помогли.
1 ответ
Эта проблема с вводом не-ASCII воспроизводится в консоли для всех версий Windows вплоть до Windows 10. Включая процесс хоста консоли, т.е. conhost.exe, не был разработан для UTF-8 (кодовая страница 65001) и не был обновлен для его последовательной поддержки.
В частности, ввод без ASCII вызывает пустое чтение, а пустое чтение считается концом файла, поэтому чтение ввода с консоли прекращается, что приводит к усеченному выводу.
Переключатель /U cmd.exe также не полезно, так как работает только для внутренних команд. Вы можете получить лучшие результаты от некоторых приложений, направляя вывод команды в файл, но файл не будет иметь метки порядка байтов UTF-8 (BOM).
Короче говоря, не ожидайте многого от chcp 65001 и вы не будете разочарованы. Единственная версия Unicode, которая хорошо работает в Windows, - это 16-битный Unicode.