Объединить два файла PDF, содержащие четные и нечетные страницы книги
У меня есть два документа PDF с возможностью поиска, скажем even.pdf а также odd.pdf которые содержат четные и нечетные страницы книги, соответственно.
Я могу декомпилировать каждый PDF в отдельные файлы 001.pdf002.pdf003.pdfи так далее. Вопрос в том, как их объединить?
Они являются четными и нечетными последовательностями, пронумерованными 1, 2, 3, Если нумерация в процессе декомпиляции с pdftk были разные, например 1, 3, 5 даже и 2, 4, 6 странно вместо 1, 2, 3, 4Я мог бы просто объединить их.
Могу ли я сделать это по-другому?
12 ответов
Простым решением было бы использовать только pdftk следующим образом:
pdftk A=even.pdf B=odd.pdf shuffle A Bend-1 output merged.pdf
С домашней страницы PDFtk:
PDFtk имеет специальную функцию, которую мы добавили специально для решения этой проблемы с организацией отсканированных страниц: случайное воспроизведение. Допустим, у вас есть два файла PDF: четные.pdf и нечетные.pdf. Затем вы можете сопоставить их в один документ, например:
pdftk A=odd.pdf B=even.pdf shuffle A B output collated_pages.pdfЕсли ваши четные страницы расположены в обратном порядке, вы можете изменить их диапазон страниц:
pdftk A=odd.pdf B=even.pdf shuffle A Bend-1 output collated_pages.pdfФункция случайного воспроизведения работает, беря одну страницу за раз из каждого диапазона входных страниц и собирая их в новый PDF-файл. Вы указываете эти диапазоны после ключевого слова shuffle, и вы можете иметь более двух диапазонов.
Пример использования большего количества диапазонов:
pdftk A=odd.pdf B=even.pdf shuffle A1 B1 A5-6 B2-3 output out.pdf
в этом случае выходные данные содержат первую страницу A (A1), первую страницу B (B1), затем пятую страницу A, вторую B, шестую страницу A и, наконец, третью страницу B.
Проверьте Сейда - новый расширенный онлайн инструмент для работы с PDF
Он имеет возможность объединять документы различными способами и может быть в состоянии выполнить ваши требования выше - задача Alternate and Mix, кажется, выполняет то, что вы просите.
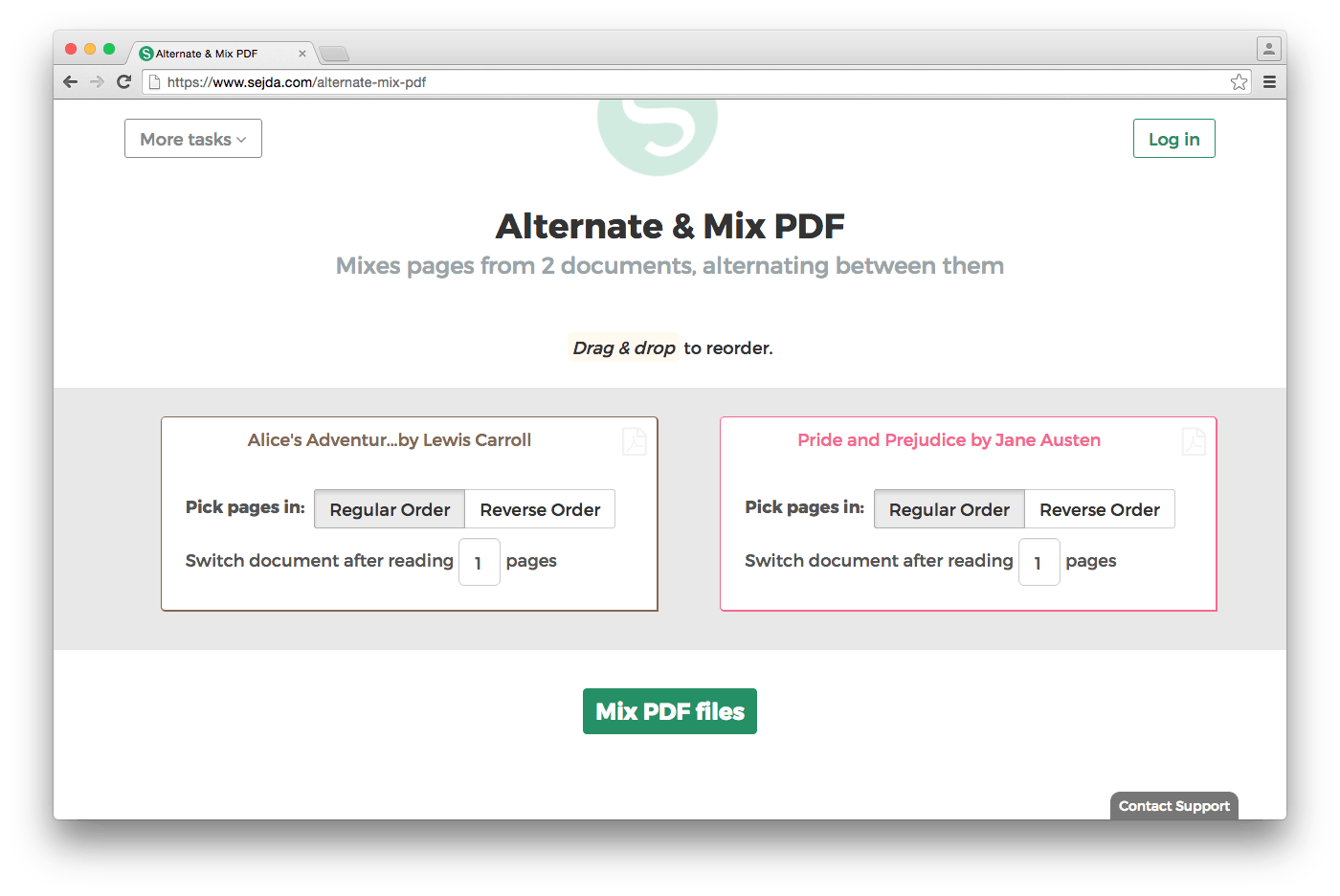
Я использую бесплатный модуль PDF Split and Merge с открытым исходным кодом, который называется Alternate Mix.
Помимо возможности объединения файлов, он способен выполнять другие интересные операции.
Из головы я бы совмещал pdftk с mmv:
- Сначала разбейте оба файла в отдельные каталоги, получив
even/001.pdfа такжеodd/001.pdfи т.п. - Тогда используйте
mmv '*.pdf' '#1-a.pdf'в нечетной папке,mmv '*.pdf' '#1-b.pdf'на четной папке. - Переместить все в одну папку. Расширение оболочки
*теперь следует сортировать нечетные страницы перед четными (001-a, 001-b, 002-a, 002-b и т. д.). - Используйте pdftk как в
pdftk *.pdf cat output combined.pdf
Возможно, вам придется делать последний бит в циклах, скажем, для первых тридцати страниц, затем еще для тридцати страниц и т. Д., В зависимости от того, насколько надежно ваше расширение оболочки со многими файлами.
Я потратил час на поиски решения для обработки трех огромных файлов, пока не нашел этот форум и не попробовал http://sejda.com/. Он проделал потрясающую работу - именно то, что я хотел: объединить два документа (один, содержащий нечетные страницы, и второй, содержащий четные страницы в обратном порядке). Отличный онлайн-сервис, который я бы рекомендовал всем, кому нужно обрабатывать большие PDF-файлы. Спасибо команде Сейда!
PDFSam Basic бесплатен, и процесс слияния происходит намного быстрее, чем я привык в Adobe Acrobat. (Для объединения двух 200-страничных файлов по 50 МБ с чередованием потребовалось около 3 секунд. Тогда как в Adobe Acrobat это заняло бы не менее 10 секунд, без функции чередования.)
Единственным возможным недостатком является то, что вы должны установить его в своей системе.
Я столкнулся с той же проблемой. Один файл, содержащий нечетные, один файл, содержащий четные страницы отсканированной книги. Я просто использовал встроенную возможность пакетного переименования Windows 7/8/8.1.
1) Разделите страницы каждого файла PDF на отдельные файлы для каждой страницы, чтобы одна папка содержала все нечетные страницы как отдельные файлы, а другая папка содержала все четные страницы.
2) Массовое / пакетное / массовое переименование файлов обеих папок одинаковым образом. Просто выберите все файлы в каждой папке и переименуйте первый как a и нажмите Enter. При этом файлы в каждой из двух папок будут пронумерованы как (1), a (2), a (3)...
3) В папке с нечетными страницами скопируйте все файлы и вставьте их прямо в ту же папку. При этом он создает копии файлов с нечетными страницами, которые будут выглядеть как (1) - Копировать
4) Переместите эти скопированные файлы в папку, содержащую четные файлы. Это сортирует их перед четными файлами страниц (если файлы отсортированы по их именам).
5) Объедините файлы обратно в один файл, просто следуя новой схеме именования.
Чтобы объединить и разделить PDF-файлы, я использовал pdfIll's Pdf Tools, который доступен бесплатно.
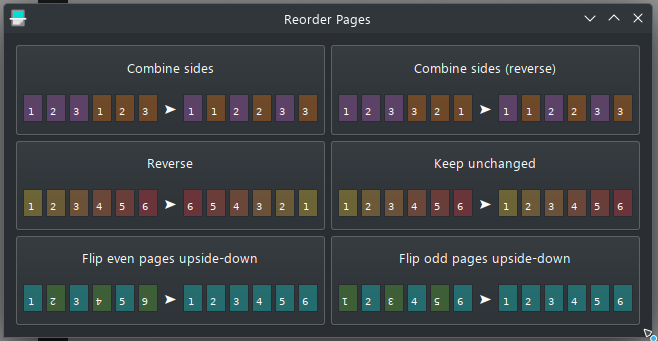
Если вы сначала сканируете документы спереди, а затем сзади, приложение GNOME «Сканер документов» (простое сканирование) может объединить сканы с помощью инструмента «Изменить порядок страниц». «Объединить стороны» — это вариант, который вы ищете:
С использованиемqpdf:
qpdf --empty --collate=1 --pages A.pdf B.pdf -- out.pdf
Ну, то, что вы спрашиваете, немного сложнее, но для начала вы можете попробовать что-то вроде Combine PDFs Free или любую другую страницу. Если у вас есть проблемы, дайте мне знать, и я могу попробовать помочь:P
С уважением Cam
Я думаю, что он выбирает немного больше гибкости в функциональности. Это делает ваш параметр combpdf совершенно бесполезным. Лучше попробовать онлайн PDF. Это даст вам командование по крайней мере...