Электронная таблица: создать столбец на основе одного столбца, отсортированного по значениям другого
Я хочу создать новый столбец данных из одного столбца, отсортированного по другому столбцу.
Проще всего объяснить на примере. На самом деле это не то, чем я занимаюсь, но я думаю, что это хорошо объясняет. Допустим, столбец А имеет имена людей в алфавитном порядке:
Адам
Бетти
Colin
Дебби
а в столбце B указан год их рождения:
1985
1973
1954
1973
Я хотел бы создать столбец C, в котором перечислены имена людей по годам их рождения:
Colin
Бетти
Дебби
Адам
Это должно быть сделано без изменения или сортировки столбца A или B.
Это должно быть сделано способом, который автоматически обновит столбец C, если столбец A или B отредактирован.
Спасибо! (Я работаю в Excel на Windows 10, если это имеет какое-либо значение.)
3 ответа
@ Студент Гарри по какой-то причине я не нашел формулы, которые мне были нужны раньше. Когда я не мог вернуться на эту страницу в течение нескольких дней, немного больше исследований нашло мне формулу RANK. (В новейшем Excel значение RANK обесценивается, поэтому я использовал вместо него более новый RANK.EQ. А потом я подумал о VLOOKUP, но, немного углубившись в поиск, я нашел INDEX MATCH, который выглядит лучше, и вы тоже это использовали.
Итак, вот что я придумал и как справился с дублированием лет: ранжирование имен в таблицах по годам
(Мои формулы начинаются со строки № 2 из-за заголовков)
Столбец C формулы:
=RANK.EQ(B2,B$2:B$15,1)
Важно знать, как работает рейтинг. Если в позиции № 5 есть три предмета, все они получают ранг 5, и не будет предметов с рангом 6 или 7. Следующая позиция - ранг 8.
Столбец D формула:
в первой камере
=C2
и в последующих клетках
=C3+COUNTIF(C$2:C2,C3)
Это избавляет от дублирования рейтинга. Рейтинг увеличивается на 1, если в списке есть повторяющийся рейтинг выше. Таким образом, этим двойным номерам 5 будет присвоен ранг 6 и 7.
Столбец E - это просто список последовательных чисел, который довольно легко заполнить.
Формула столбца F объединяет все это:
=INDEX($A$2:$A$15,MATCH(E2,$D$2:$D$15,0))
Во всяком случае, я хотел бы поделиться тем, что у меня было, как оно работает, и немного по-другому. Но, вероятно, ответ от ученика Гарри лучше, так как он использует меньше столбцов, чтобы добраться туда. (Возможно, я мог бы объединить некоторые и использовать меньше столбцов с моим методом.)
Cx=INDIRECT(ADDRESS(COUNTIF(B:B,">=" & Bx),1))
Значения года рождения должны быть уникальными.
Если данные начинаются со строки с номером больше 1 - добавьте правильное число к значению COUNTIF().
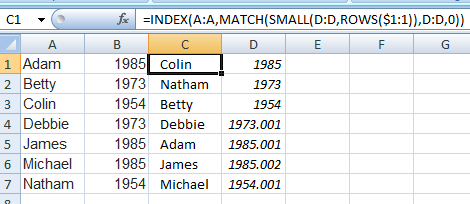
Это было бы легко, если бы годы в столбце B были уникальными, но мы можем скорректировать дубликаты лет. В D1 введите:
=B1
и в D2 введите:
=B2+COUNTIF(B$1:B1,B2)*0.001
и скопировать вниз. Столбец D повторяет столбец B с дубликатами "не конфликтует". Это позволяет MATCH() функция для извлечения всех значений. Наконец, в C1 введите:
=INDEX(A:A,MATCH(SMALL(D:D,ROWS($1:1)),D:D,0))
и скопировать вниз: