Как превратить отношение "много" на основе строк в макет на основе "одного" столбца
Простите за мой английский. Я ищу метод преобразования данных для набора продуктов. У меня есть набор данных, в котором атрибуты перечислены в строках, и я хочу, чтобы эти атрибуты были заголовками столбцов, ссылающимися на значения и которые соответствуют этим атрибутам и продуктам, с которыми они связаны. Мой лучший пример будет следующим (для одного продукта):
Должен быть преобразован в:
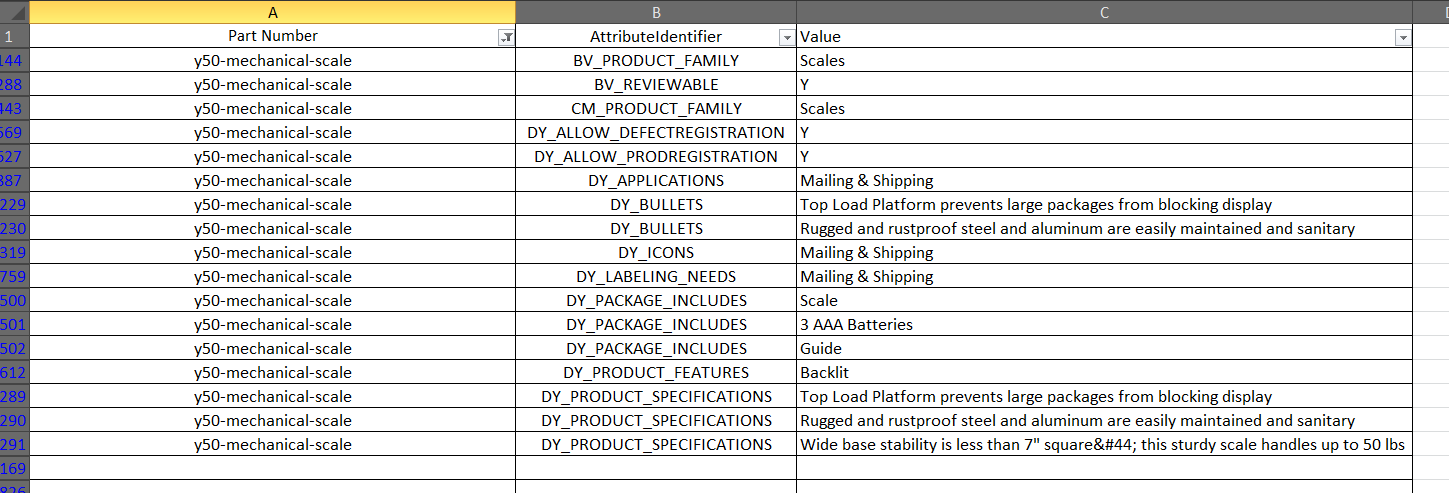
Существуют тысячи отдельных "номеров деталей", поэтому простая транспонирование не обрезает их…
1 ответ
Это немного глупо, но оно должно работать, если мои "Допущения и интерпретация" верны.
Допущения и интерпретация
Предположение 1. Все ваши номера деталей уникальны, а ваши AttributeIdentifiers абсолютно одинаковы для атрибутов, которые вы хотите представить в каждом столбце во всех частях.
Предположение 2: AttributeIdentifiers уникальны в каждой части, то есть никогда не будет двух строк, имеющих одинаковый AttributeIdentifier и один и тот же номер детали.
Предположение 3: Исходные данные имеют заголовки в строке 1, а данные заполняются непрерывно, начиная со строки 2.
Предположение 4: Исходные данные выложены аналогично предоставленным скриншотам. "Номера деталей" находятся в столбце A, а "AttributeIdentifiers" - в столбце B, "Значения" - в столбце C, и на листе нет других данных, относящихся к этой проблеме.
Интерпретация. Вы хотите, чтобы номера деталей оставались в столбце A, а все атрибуты этой детали указывались в одной строке под заголовками в соответствии с их AttributeIdentifier.
Решение
- Создайте новый лист в той же книге.
- Назовите первый лист
Old Dataи второй листNew Report, - копия
'Old Data'!A:Aв'New Report'!A:A, - Выполните "Удалить дубликаты на
'New Report'!A:A, - копия
'Old Data'!B:Bв'New Report'!B:B, - Выполните "Удалить дубликаты" на
'New Report'!B:B,- Убедитесь, что вы не расширяете выделение за пределы этого столбца для этой операции.
- удалять
'New Report'!B1и сдвиньте оставшиеся ячейки в этом столбце вверх. - Выберите все ячейки, в которых есть данные
'New Report'!B:B, Скопируйте эти ячейки и используйте "Paste Special" и "Transpose", чтобы вставить их, начиная с'New Report'!C1, - удалять
'New Report'!B:B, Удостовериться'New Report'!C:Cсдвигается, чтобы занять свое место. - Добавить новый столбец слева от
'Old Data'!A:A,- Примечание: это сместит все столбцы вправо, так что "Номер детали" будет в столбце B и так далее.
- (Необязательно) Набор
'Old Data'!A1вUID,
- Задавать
'Old Data'!A2в=CONCATENATE(B2,C2), - копия
'Old Data'!A2вниз по всему столбцу, до конца набора данных. - Задавать
'New Report'!B2чтобы:=IFERROR(VLOOKUP(CONCATENATE($A2,B$1),'Old Data'!$A:$D,4,FALSE),""), - копия
'New Report'!B2вниз по оставшейся части столбца, до конца набора данных. - Скопируйте все ячейки в
'New Report'!B:B, начиная с'New Report'!B2и заканчивается в конце набора данных, через оставшиеся столбцы справа. - Выберите весь
'New Report'простынь. Скопируйте его и вставьте на место "Как значения", чтобы заблокировать данные. - (Необязательно) Удалить
'Old Data'!A:A,
Пояснение к шагу 14
Короче говоря, формула ищет в "Старые данные" подходящее значение для размещения в ячейке в соответствии с "Номером детали" и "AttributeIdentifier". Если ничего не найдено, ячейка останется пустой.
Примечание. Я лично не тестировал это решение для вашего случая использования. Тем не менее, я достаточно знаком с этапами, чтобы быть уверенным, что он будет работать для вас без особых изменений. Пожалуйста, дайте мне знать, если у вас возникнут ошибки.