Двигатель Regexp ведет себя плохо в Atom
Я пытаюсь удалить все строки, начинающиеся с пробельных символов, из большого текстового файла с помощью Atom. Я использую регулярное выражение ^[\s]+.*$, Проблема в том, что он выбирает не только строки, начинающиеся с пробелов, но и одну строку после них. Файл в формате UTF-8 и большинство символов кириллицы. Что я делаю неправильно?
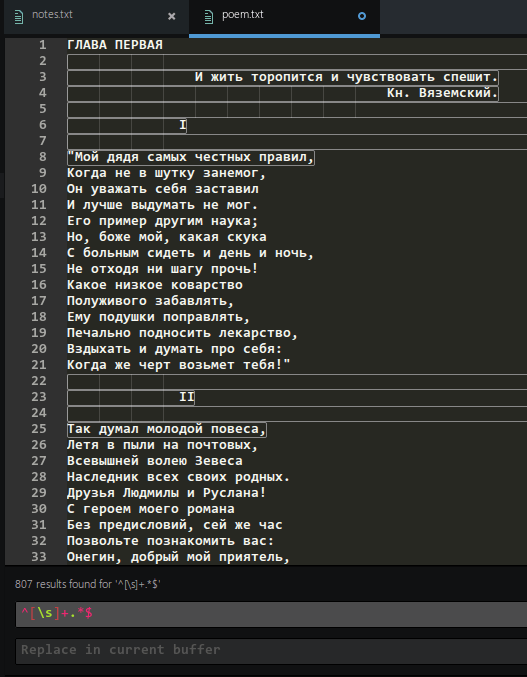
1 ответ
Решение
- Цель: удалить любую строку, начинающуюся с пробела, включая новую строку в конце.
- Шаблон для использования:
^\n|(^[ \t]+.*\n*) - Примечание:
[\s]будет соответствовать любому пробелу. В то время как[ \t]будет соответствовать пробелам и символам табуляции.