MS Excel: подсчитывать частоту сходных значений между пустыми ячейками
Я бы хотел посчитать частоту одинаковых значений в строке. Значение должно занимать как минимум две ячейки и быть рядом друг с другом.
Я хотел бы разместить изображение здесь, но у меня недостаточно репутации. В любом случае, скриншот можно найти здесь: https://www.dropbox.com/s/1em9ltssc1ruw0u/stackOverflow_excelIssue_Countfrequencyofsimilarvaluesinbetweenblankcells.jpg?dl=0
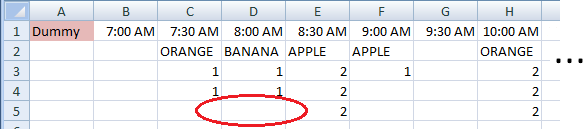
J7: BE7 - это то, где человек будет вводить значения - это соответствует времени с шагом 30 минут.
На другой части того же листа, в этом случае DD7:EY7, где у меня работают формулы.
Эта формула включена (первый столбец) DD7 - COUNTIF(J7:$BE7,J7)
Эта формула включена (последний столбец) EY7 - COUNTIF(BE7:$BE7,BE7)
Формула в DD7 подсчитывает, сколько раз значение в J7 появляется в строке 7 от столбца J до BE.
Сценарий 1: Эта формула прекрасно работает, если "оранжевый" появится только один раз. на моем примере из K7:L7.
Сценарий 2: Проблема в том, что "оранжевый" снова появляется в непоследовательной ячейке. то, что я имею в виду, "оранжевый" появляется на K7:L7, затем он появляется снова на P7:Q7.
в сценарии 1 результат формулы при проверке K7: L7 равен 2, что является желаемым значением.
в сценарии 2 результат формулы при проверке K7: L7 равен 4, поскольку он также будет считать "оранжевый", который появляется на K7:L7.
Я надеялся, что подсчет прекратится, если M7 будет иметь другое значение. K7:L7 содержит "апельсин", а M7:N7 - "яблоко". или подсчет остановится, если между ними будет пустая ячейка, например, U7: V7 содержит "гуаву", а T7 пусто, тогда X7: Y7 снова имеет "гуаву".
плоды могут занимать от двух до сорока восьми столбцов каждого ряда.
Я знаю, что это многословно, но я не могу найти другие способы объяснить это, английский не мой первый язык.
Заранее благодарю.
~ знак
1 ответ
Если я правильно понимаю ваш запрос, следующие формулы будут работать. Моему решению требуются фиктивный столбец и вспомогательный ряд, но они могут быть скрыты. Кроме того, вы, вероятно, можете устранить пустую колонку с небольшим количеством работы, и вы можете поместить строку помощника в любом месте.
Я предполагаю, что имена ваших клиентов находятся в строке 2. Я буду использовать столбец A в качестве фиктивного столбца, поэтому данные о встречах начинаются со столбца B. Строка 3 будет вспомогательной строкой. В ячейку B3 введите формулу:
=IF(B2="", "", IF(B2<>C2, 1, C3+1))
Имея в виду:
- Если B2="", имя клиента для этого временного интервала будет пустым, поэтому это временной интервал простоя, поэтому отображайте пустым.
- В противном случае, если B2<>C2, этот временной интервал и следующий имеют разных клиентов (C2 может быть или не быть пустым), так что это последний временной интервал для этого назначения. Представьте его как 1. В противном случае посчитайте в обратном порядке, поэтому второй до последнего временной интервал для этого назначения равен 2, с третьего по последний временной интервал равен 3 и т. Д.
В ячейку B4 введите:
=IF(A2<>B2, B3, "")
- Если A2<>B2, этот временной интервал и предыдущий имеют разных клиентов (A2 может быть или не быть пустым), поэтому это первый временной интервал для этой встречи. Покажите B3, который показывает, сколько временных интервалов (полчаса) есть в этом назначении. В противном случае отобразите пустым.
Вот ваши данные с этими формулами:

(Приведенное выше изображение ссылается на полный.)
Я изменил данные GUAVA, чтобы лучше проиллюстрировать, как это работает:
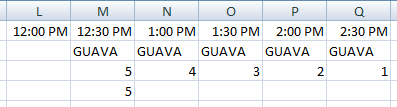
Вы говорите: "Значение должно занимать как минимум две ячейки…". Если я правильно понимаю, вы можете изменить формулу в строке 4 на:
=IF(AND(A2<>B2,B3>1), B3, "")
то есть, отображать значение B3, только если оно> 1. Это показывает первую формулу строки 4 в строке 4 и модифицированную формулу в строке 5: